首页
>>
厂商
>>
CTI系统平台厂商
>>
北京欣方
发表评论
分享按钮
语音识别技术在自动外呼和洗号系统的应用与优势
2011/07/18
摘要
:
随着呼叫中心系统呼出业务量的不断增多,正确识别号码状态,提高拨号效率已经成为外呼型呼叫中心需要解决的重要问题。本文首先介绍了号码识别在自动外呼和洗号系统中的意义,接着分析了信令分析检测方式的不足,进而提出一种基于语音识别技术的外呼系统,并阐述了语音识别技术在提高工作效率及降低成本上的优势及意义。
关键词
:呼叫中心;自动外呼;洗号;语音识别;
1.引言
随着呼叫中心市场的不断成熟,呼入型业务基本饱和,通过电话由坐席主动对客户进行拜访和推销产品的呼出型业务正逐步成为赢得客户的关键手段。而如何对外呼号码进行准确识别和筛选(“洗号”),以通过提高拨号效率来提升营销利润,已经成为迫在眉睫的问题。
现有的自动外呼及洗号系统中的号码识别方法一般是通过信令处理等技术来实现,而基于信令检测的方式在准确性和效率保证上又存在严重的问题。
为了提高号码识别的准确性与效率,提出了一种基于语音识别技术的号码识别方法,可应用于自动外呼和洗号系统。该方法通过与信令检测方法相结合,可使自动外呼和洗号系统中的语音识别准确率达到95%以上;有效解决了传统外呼和洗号系统中现存的弊端,很大程度上提高了拨号效率,从而达到了提高呼叫中心效益的目的。
2.自动外呼和洗号系统
自动外呼系统是一个自动执行企业用户定制的外呼任务的系统。它执行的特点是系统根据座席状态和算法策略对指定号码集自动发起呼叫,通过分析呼叫过程中的信令和信号,对呼叫采取合适的处理。具体处理方法为:当呼叫接通时,系统将呼叫转接给座席;若用户未接通,则继续呼叫下一个号码,同时代替座席记录当前呼叫的状态。
洗号系统也是自动外呼系统的一个重要应用,其原理是系统提前将杂乱的号码试呼一遍,清除一些无效号码,如空号、停机、欠费、格式错误等,以此来提高外呼效率。
值得注意的是,自动外呼和洗号系统都需要通过号码识别来确定所呼号码的状态,系统的效率很大程度上取决于其对号码的识别能力。然而,目前常见的号码状态分为多种类型:
号码不可用(空号,停机,欠费,地址不全等);
暂时不可用(关机,不在服务中,通话中等);
可用(无应答,被叫忙等)、自动应答号码(传真、企业总机等)。
由于三大运商营对如此繁多的号码状态未作统一标准,加上信令检测方式存在很多弊端,使得对号码的识别具有相当大的挑战。首先,错误的识别会导致部分数据的丢失,使企业失去一些潜在用户,直接导致利益损失。其次,识别速度过慢,不但影响系统的整体效率,还会影响座席人员的工作热情,这也成为了提高企业利润的瓶颈。因此,如何对号码进行正确、高效的识别是当前要解决的关键问题,这也使得对号码识别方式的研究具有了现实意义。
3.号码识别方式分析
在实际网络中,表示被叫用户状态有三种方式:标准Tone音、提示音和7号信令。每种方式又可细分为多种表现形式:
标准的Tone音
:振铃音,忙音,空号,不可达音等,这种方式在固定网中比较常见。
提示音
:“该号码不存在”,“该号码是空号”,“该号码已停机”等。通过提示音来显示当前被叫用户状态多发生在移动网络中。
7号信令
。在呼叫释放的信令(releasecall),会带释放原因:“Unallocated Num”“user busy”等,也常被移动网络采用。
目前自动外呼和洗号系统主要采用信令分析、语音识别技术(包括检测音频)等进行号码识别和筛选。下面将对几种检测方式进行详细说明。
3.1 信令检测方式分析
一般情况下,号码识别需根据当前呼叫失败的原因来判断,因此,通常会利用呼叫过程中产生的信令来检测。然而这种检测方式存在严重的准确性和效率问题,不能满足呼叫中心自动外呼和洗号的功能要求。
首先,采用这种方式进行检测准确性差。其原因是:在中国三大运营商现网中,反映被叫用户的状态没有统一的标准。甚至同一个运营商的同一个本地网都会出现不相同的情况。标准的不统一,为信令的检测造成了困难,经常出现号码状态无法识别、错误识别的情况。
其次,采用信令检测方式效率低下,由于PSTN普遍实施了呼叫失败后语音提示的人性化功能,语音提示时长可达60秒,然后才发送信令。这样严重影响了信令检测的效率。
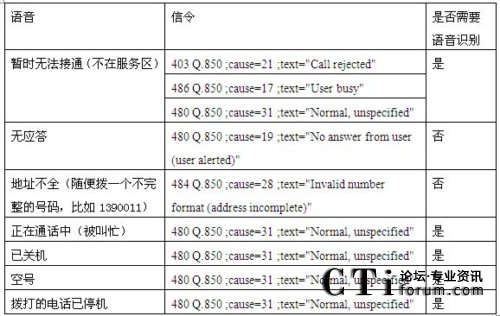
下例为对河北移动某呼叫中心自动外呼系统的信令测试结果分析(该系统使用的交换机为Dialogic IMG1010网关,信令方式为ISUP):
表1:信令号码识别测试
从归纳的情况看,只有无应答和地址不全两种情况是可靠信令分析来识别的,其他的5种情况都无法通过信令检测识别。特别是暂时无法接通的语言提示,播放完提示音有3种不同的信令,应该是属于不同的情况,但是放了相同的语音。因此造成号码识别错误的现象。
综上,信令分析检测方式,对于释放7号信令来表示用户状态的情况是十分有效的。但是,该方式不具备区分标准Tone音和提示音的能力,同时效率低下。要准确、高效的判断用户的当前状态,必须要通过一种更为准确可靠的方式――语音识别。
3.2 语音识别检测方式分析
现有PSTN网络普遍实施了呼叫失败后语音提示或tone音的人性化功能,由于这些tone音和失败提示音都是在临时话路中播放的,因此信令的方式无法区分这两种场景。但是语音识别技术恰恰是利用了这个特点,对语音提示或tone音进行快速的语音识别与匹配,在精确识别号码的同时,提升了识别的速率。
首先,采用语音识别技术可帮助自动外呼和洗号系统提高号码识别的准确率。系统通过语音匹配将相同信令的呼叫区分,帮助洗号系统正确的识别可用号码,同时还能帮助自动外呼系统正确的记录座席呼叫状态,避免了因错误识别而导致数据丢失的情况发生。
其次,语音识别技术还可以帮助自动外呼和洗号系统实现高效识别。系统通过特征和关键字匹配的方式,在几秒钟内就能完成语音匹配,帮助自动外呼系统真正的提高了座席工作效率;同样也帮助洗号系统提高了效率,使其以更少的设备投入获得更好的效益。
综上,采用语音识别技术,进行模式匹配,可以精确、高效的识别号码状态,弥补了信令检测方式的不足。但是语音识别技术也存在一些难点,例如,样本库的建立、方言识别以及提高识别效率等等。这些技术难点也成为了语音识别检测方式需要解决的重要问题。
4.语音识别技术的应用
4.1 基本原理
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术。语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术三个方面。它可用于对用户呼叫失败的情况进行自动分类。
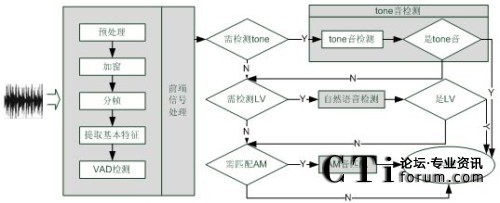
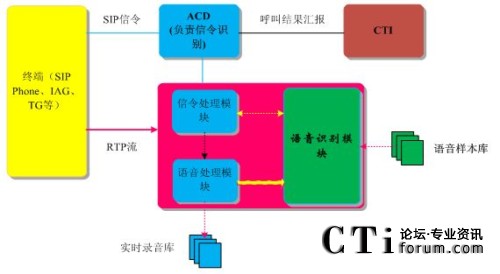
我们采用的语音识别技术主要靠匹配方式来进行,分成Tone音匹配、AM音匹配和人类自然语音检测三部分。具体流程图如下:
图:语音处理流程图
(VAD: Voice Activity Detection;LV: Live Speech;AM: Answering Machine)
图中,Tone音匹配采用模式匹配方法,可以实现对振铃音,忙音,空号,不可达音等100多种标准提示音的识别。AM(Answering Machine)音匹配主要负责识别传真机、自动答录机等机器语音,同样采用模式匹配方法,将收到的语音与标准样本库进行比对。人类自然语音检测的功能主要通过人真实声音的检测,来判断是否需要进行语音匹配。
4.1.1 标准Tone音匹配
Tone音匹配采用的是模式匹配方法,将模拟语音信号转换为数字信号,再同音库中的样本进行比对,实现号码状态识别。
在标准Tone音匹配模块里,因为某些单频Tone音的频率区间和DTMF之间存在重叠,为了避免不必要的混淆,采取顺序检测,即首先检测是否是DTMF,再检测是否是单频的Tone音。
Tone音的一个显要特点是在频域上的某一个子带上的能量特别强,而且这种情况是在后续所有非静音的连续帧上都是持续的(如图1所示)。基于此特点,我们采用以下方法:
1.取第一帧非静音帧的16个子带能量特征,求出其最大子带能量所在的子带序号(在DTMF阶段是取最大的两个子带序号)。
2.如果最大能量值所在的子带序号一直保持若干帧不变,则我们认为从频率角度满足了作为一个Tone音的基本条件。
由于DTMF不存在时间持续长短的相关信息,所以经过上述步骤后,只需将最大能量的两个序号在事先准备好的DTMF子带序号表里查找即可得出结论,对于检测DTMF显然已经足够。但由于单频的Tone音还存在持续时间长短及静音间歇的问题,故对于输入的信号,经过前端数据处理过程之后,要利用它是否静音帧的信息统计各段长度,最后,同时考虑频率和时间段列表,如果满足库中某一条的相关标准,才认为是一个标准Tone音。
4.1.2 AM音匹配
AM音匹配同样采用模式匹配方法,对语音信号进行采样、量化、归一化处理后,将模拟语音信号转变为数字语音信号。再与库文件中的特征模板进行比较,选择出最为相近的一条作为匹配结果返回。
假设模板库里的特征条目的时长应该至少是一个完整的AM音模板,因此从时间长度上来看,输入的待检测语音长度应小于模板里的最佳匹配项。
不像Tone音检测模块中使用的是各帧在前端处理过程中产生的16个子带上的能量具体值,这里使用的特征却是经过归一化后的二进制向量。如果要比较的两帧特征向量分别设为:
其中, 指异或操作,而函数 是求二进制向量里“1”的个数。
然后,如果输入语音样本的帧数目为 ,则总距离定义为相应的 帧距离的和。
至于要得到这条语音样本与特征库里某个模板的最小距离,比较传统的方法是用这待匹配的 帧同模板的开始处 帧算距离,然后将待匹配音顺次后移,一直到末端为止,得到的最小距离就是这个输入样本同这一模板的距离。然后,在实际实现过程中,因为对算法性能要求比较高,可以考虑加入不同的索引而达到减小计算次数的目的。索引的种类和方法不一而足,在此就不再赘述了。
4.1.3 自然语音(Live Speech)检测
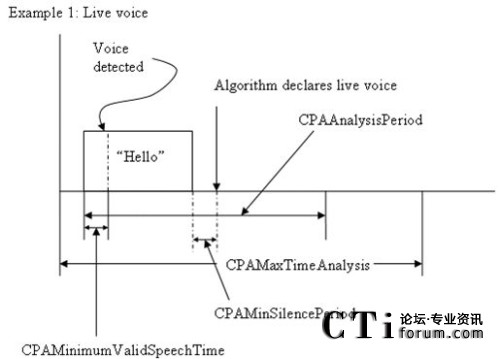
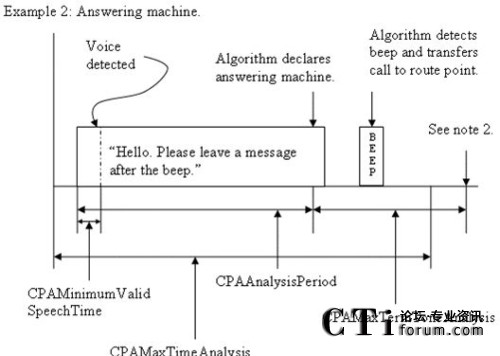
该部分的主要功能是利用人类自然语音特有的一些规律进行启发式判断,从而确定是否需要进入Tone音或AM音识别流程。该部分采用的规律如下:
A.如果正式语音之前的静音段超过某一阈值,则认为是人类自然语音
B.如果问候语过长,时间上超过某一阈值,则认为是应答机录音。
C.如果问候语之后的静音段过长以至于超过某个门限,则认为是人类自然语音。
D.如果问候语中的词语数目过多,则认为是应答机录音。
除此之外,我们还设定了一个检测最大时间,如果超过这一时间还没有一个检测结果,则返回一个“无法判断”的结果。
最后,相关参数、时间以及判断结果的关系如图所示:
图:人类自然语音情况下各参数相对于时间轴的说明
图:自动应答机录音情况下各参数相对于时间轴的说明
5.产品与应用
根据以上语音识别的方法,设计了基于语音识别技术的自动外呼和洗号系统。以下部分将对该产品的框架及模块进行介绍。
5.1 技术架构
图:系统技术架构
上图为基于语音识别的自动外呼和洗号系统的技术架构,由接入部分和平台部分组成。其中终端为接入部分,提供包括PSTN传统交换机、NGN软交换和内部分机终端等多种网络和终端的接入能力。平台部分由ACD、CTI和MS等节点组成,提供呼叫中心语音接入、控制、管理和路由等功能。
ACD是呼叫中心的核心控制系统,主要负责呼叫中心信令、呼叫与控制节点,负责信令识别。支持呼叫中心业务触发到CTI。
CTI提供座席资源管理和排队、路由策略,支持座席接入,同时支持MS的访问。
MS(Media Server,媒体服务器)是NGN架构中提供所有媒体资源的设备,是呼叫中心媒体汇聚与统一处理点,所有的媒体资源处理都有MS来完成,包括IVR、DTMF、会议、录音、传真等。在媒体服务器上加入语音识别模块,对收到的RTP语音流进行实时的匹配和识别。
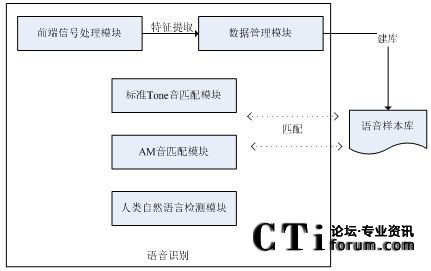
MS中新增加的语音识别模块,由前端语音数据处理模块、数据管理模块、标准Tone音匹配模块、人类自然语音检测模块、AM音匹配模块五部分组成,共同完成语音识别检测。其模块组成如下:
图:语音识别的模块组成
前端语音数据处理模块,用来对语音进行预处理和特征提取。数据管理模块,主要工作为建库。标准Tone音匹配模块,匹配标准Tone音。人类自然语音(Live Speech)检测模块,进行人类真实接听语音的判断。AM音匹配模块,从库中匹配合适的模板音和判断是否为库外音。
前端语音数据处理模块
该模块负责进行语音识别的第一步:预处理和特征提取。该模块在模块处理中的地位非常重要,对于数据管理模块来说,AM库文件的每一条内容是经过前段语音数据处理以后的特征;而后面的三个检测或匹配模块都是建立在前端数据处理以后的数据基础之上的。因此,前端语音数据处理的方法和所选用的特征对于检测或匹配的准确率和算法的效率都至关重要。
数据管理模块
本模块的核心工作是对给定的Tone音标准和AM模板音库进行分析和特征提取,并存成相应的特征库文件。特征库主要分为Tone库和AM库,其建立过程如下:
A.Tone库
Tone库的建立过程比较简单。因为有既定的标准,不需要从模板文件中读取再生成。所以,采用的方法是直接从记录有标准Tone音标准的文本文件中逐条逐项读取,然后依样存成二进制库文件Tone.dat。
B.AM库
AM库的建立过程比Tone音库稍微复杂一些,原因是要经过从相应的pcm文件模板进行分析和提取特征的过程,因此就多了一个前端语音数据处理模块。存入库中的信息包括模板ID号、是否静音帧、模板帧数目、FFT特征序列以及归一化后的特征序列。归一化前的特征序列会用于tone音检测模块,而归一化后的特征序列用于AM匹配。
标准Tone音匹配模块
该模块的功能是进行标准Tone音匹配。该系统采取的是顺序检测,即首先检测是否是DTMF,再检测是否是单频的Tone音。
人类自然语音(Live Speech)检测模块
该模块负责判断人类真实语音。人类自然语音检测在三个检测或匹配模块中是最难处理的一块。因为本质上说,自动应答机的话音也是人通过录音机事先录好的,所以从声学层次并不能有效地将它们区分开。该系统利用人类自然语音特有的一些规律进行启发式判断,来进行人类语音的识别。
AM音匹配模块
AM音匹配模块的主要任务是将输入的语音经过处理后,与库文件中的特征模板进行比较,选择出最为相近的一条作为匹配结果返回。若经过与所有的特征模板都进行比较后得出的最小距离仍然大于某一个门限值,则认为输入语音是库外音。
同时,该系统还通过提取各地不同网络、运营商的提示音库,建立了一个庞大的样本库。目前该系统已拥有三大运营商、30多个省市的近300个样本库,可根据项目需要灵活加载部署,从而解决了方言识别的问题。
5.2 平台架构
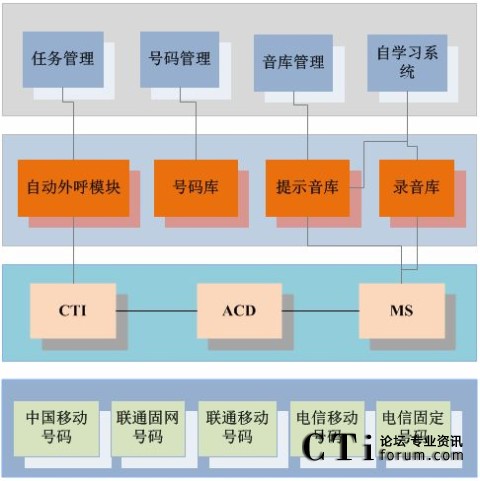
基于语音识别技术的自动外呼和洗号系统主要由管理应用、外呼与库模块、号码与识别模块三部分组成。每部分的功能如下:
图:系统组成
5.2.1 管理应用
该部分由任务管理、号码管理、提示音管理、自学系统四部分组成,任务管理负责创建洗号任务,选择号码库,设置时间速率等。号码管理可以实现包括号码导入导出,未洗号码、已洗号码分类检查,重听录音等功能。提示音导入导出,试听检测靠提示音管理来进行。自学习系统能对不能识别号码进行人工干预和二次识别,将提示音加入库,从而保证了提示音样本库的不断增长。
5.2.2 外呼与库模块
该部分由自动外呼模块、号码库、录音库、提示音库四部分组成。自动外呼模块:按指定速率进行外呼,并将呼叫结果保存入库。号码库用来保存各种号码资源,特别是有效号码,包括移动号码(联通、移动、电信),固定号码(电信、联通)。提示音库样本库覆盖了各地、运营商及网络。录音库可对洗号结果进行录音,还可用于人工抽查,并且可进行二次分析和自学习,提供增值能力。
5.2.3 呼叫与号码识别模块
该部分由CTI、ACD、MS三部分组成,也是系统的主要组成部分。CTI负责指示ACD发起外呼,上报结果。ACD控制信令检测,而MS负责提供语音导航和自动服务功能,可解析执行来实现语音交互能力,是完成语音识别的主要部分。
5.3 基于语音识别的号码识别流程
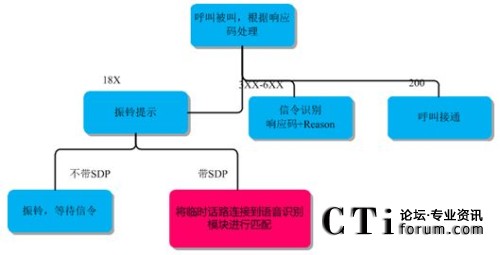
下图为该产品基于语音识别的号码识别流程,具体洗号流程如下图:
图:基于语音识别的洗号流程
洗号流程发生在呼叫建立过程中,如果存在临时话路(彩铃、tone音、各种识别提示音等情况),则进入到语音识别过程。具体:
系统发起呼叫,根据返回的信令确定下一步处理流程
如果是200响应码,表明呼叫接通,直接转到座席处理
如果是3XX-6XX响应码,表明呼叫失败,根据信令响应码和Reason原因值进行检测
如果是18X响应码,表明在振铃阶段,需要根据是否带SDP确定下一步处理
如果18X带了SDP,表明进入了临时话路,那么连接语音识别模块进行匹配处理
如果18X没有带SDP,则表明只是普通的振铃,无需识别
5.4 系统特点
语音识别技术应用于号码识别领域,对呼叫建立过程中临时话路播放的语音进行快速匹配,以实现号码快速和精确的识别具有非凡的意义。基于以上语音识别模块的洗号系统,相比单靠信令检测的洗号系统,更高效可靠。其特点如下:
准确率高
从技术方面来看,欣方公司的洗号系统目前面向PSTN(固定电话网)、PLMN(移动电话网)和NGN(软交换)网络,能够支持音频(Tone音)检测、信令(ISDN PRI、七号信令等)处理、语音识别等洗号产品关键技术,号码筛选准确率在95%以上,是国内洗号系统中有效号码识别率最高的产品之一。
支持Tone音检测功能。
在固网中,交换机使用Tone标识被叫用户状态的比较多,如正常回铃音、忙音等,欣方洗号系统针对Tone音的检测能够达到100%的准确率。
支持7号信令和ISDN PRI信令。
在标准的信令处理方面,被叫的交换机会主动释放呼叫(Release),并在信令中包含释放原因,如“Unallocated Num”(空号)、“User Busy”(被叫忙)等。欣方洗号系统在信令处理方面能够达到100%的准确率。
支持交换机网络提示音的检测。
这是欣方洗号系统中最具难度、同时也是最具技术含量的部分。由于国内三大电信运营商在语音提示反映被叫状态方面,没有统一的标准。例如,同样是被叫为空号的提示音,可能是“对不起,您拨的号码是空号”,也可能是“对不起,您拨的号码不存在”等等。为此,欣方洗号系统配置了一个可扩展的音库,将各种提示音以及其具体的含义定义在里面。目前音库中包含固网提示音600多条,移动提示音100多条,基本上覆盖了三大运营商全国各省的网络提示音。
具备自学习的语音识别能力。
由于国内三大电信运营商(特别是固网运营商)存在太多的不同品牌交换机,并且各个本地网的提示音经常不相同(有时候即使提示内容相同,但是提示音的音调、语气也可能不同),这就对洗号系统的语音识别能力提出了更高的要求。欣方洗号系统对外呼采用会议方式进行全程录音,会议方式录音保证了录音的可靠性。用户通过对错误检测录音的分析,可以生成新的语音识别样本库,动态加载到系统中。从而进一步提高识别精准度。这种自学习的语音识别功能,保证了欣方洗号系统所具备的高识别率。
系统处理能力强。
欣方洗号系统中单个呼叫在5秒内完成语音检测,并结束呼叫。单个E1的配置情况下,每小时可以实现并发外呼8000个号码。
系统稳定、性价比高
欣方洗号系统软件采用C++语言开发,运行于Linux环境下。由于使用的是呼叫中心、智能网平台同一套底层代码,因此系统稳定性非常高,是电信级的产品。同时,硬件成本低,根据用户成本,可以分别配置工控机+板卡或PC服务器+语音网关的方式。同时该平台具有良好的扩展性,单台机器可支持最少1E1,最大64E1的ISDN PRI或ISUP接入。
具有重呼机制:
对于语音识别出的用户失败的情况,例如用户忙、无应答、不在服务区等情况,系统可设置重呼策略,包括重呼时间和重呼次数的设置。例如设置在10分钟后重呼、重呼次数为2次,则在第1次呼叫失败完毕后的10分钟后进行第1次重呼,若第1次重呼时还是无应答等情况,将在接下来的10分钟后进行第二次重呼。
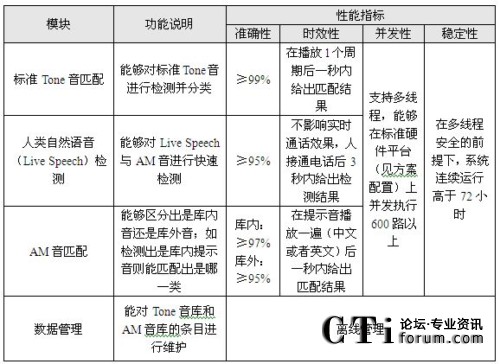
6.测试结果
通过拨打固定电话、手机、软电话、传真机等通信终端,对语音识别部分每个模块的准确性、时效性、并发性和稳定性进行了测试,结果如下表:
表2 语音匹配系统系统功能表
从测试结果可以看出,该系统能与各种可能的回传语音进行匹配,实现准确、高效的语音检测分类功能。
7.成功案例
欣方综合信令识别和语音识别技术,为自动外呼和洗号系统提供了完善的技术方案,典型案例如下:
信元博雅固话洗号平台
系统配置:工控机+板卡,1E1(ISDN PRI接入)
目标号码:全国固话号码(电信、联通)
洗号速率:并发20个呼叫,平均每个呼叫6-7秒,平均8000号/小时,20万个号/日
识别准确率:95%
接通率:<1%
河北移动卓望洗号平台
系统配置:PC服务器+网关,4E1( ISUP接入)
目标号码:河北移动手机用户号码
洗号速率:并发120个呼叫,平均每个呼叫6-7秒,平均48000号/小时,120万个号/日
识别准确率:99%
接通率:<1%
8.结束语
本文提出了一种基于语音识别的检测方法,该方法采用模式匹配对tone音、AM音进行快速匹配,可以准确地识别号码状态,很好的弥补了信令检测方式的不足,很大程度上提高了号码识别的准确率与效率。
目前,基于语音识别的检测方法已经产品化,并成功的应用到河北移动卓望和信元博雅固话洗号平台上。经过测试,该系统具有良好的并发性与稳定性,同时通过对号码的有效甄别和筛选,显著减少了座席等待时长,显著减少了座席等待时长,提高了拨号效率,进而降低了外呼成本。
随着呼叫中心市场的成熟,基于语音识别检测方法会对提高呼叫中心的效率、增加企业利润具有重要意义,其应用前景将十分广阔。但是在号码识别领域,仍有许多值得研究的问题。例如,随着样本库的扩增,号码识别的准确度和效率也会随之下降,因此采用区别于模式匹配的ASR语音识别方法来进行号码识别,将是我们研究的下一个重点。
共 4 页:
1
2
3
4
作者供稿 CTI论坛编辑
相关阅读:
北京欣方承建河北博岳外呼呼叫中心系统
2011-07-15
案例:河南农信部署ITSM服务平台
2011-06-10
欣方中继网关CIN-MG
2011-05-10
欣方外包呼叫中心及电销企业洗号系统方案
2011-05-09
欣方多媒体呼叫中心系统解决方案
2011-05-06
热点专题:
语音合成TTS 语音识别ASR
呼叫中心
电话营销